Developing these stories helped us to focus in on the explicit goals and objectives of SFM, resulting in the new scope above. The following stories reached a level of consensus on our team at GW, but we expect these to evolve as we proceed with development.
Basic researcher
Estelle, an undergraduate, has been assigned a paper to analyze the social media presence of her state’s congressional delegation. She has identified a set of twitter handles, twitter hashtags, tumblr blogs, and flickr usernames for the congress members, their campaigns, and related organizations. For each of these, she would like to collect items from the past, as well as new items. Estelle is only interested in items from the identified handles/hashtags/blogs/usernames; she is not interested in related items (e.g., retweets or mentions).
Estelle selects SFM to collect the social media she requires for her research. She contacts the SFM team about her research need. An SFM admin creates a new user account (linked to her university account) and a group account for her.
Estelle logs into SFM using her university credentials. She chooses to create a new collection and is prompted for a collection name and collection description. Estelle enters a collection name and collection description and is presented with a message that the collection has been created.
[Create / select credentials for platform]
With the collection created, Estelle must provide seeds for this collection. She is given a choice of entering twitter user timelines, a twitter stream, twitter searches, tumblr blogs, tumblr tags, flickr usernames, flickr tags, or flickr searches. Each choice is accompanied by a short explanation, so she is able to determine the type of seeds she needs.
Estelle has a long list of twitter handles, so she chooses twitter user timelines first. Estelle is prompted for a name for the set of twitter handles (a default name is provided), the list of handles, some additional collection options, and a collection schedule. She accepts the default name and cuts and pastes in her list of twitter handles. She chooses the option to also collect images found in tweets. Estelle leaves a number of default options unchanged, including: the harvesting schedule of once daily; performing differential harvests of user timelines (i.e., new tweets only) instead of full harvests; and receiving daily email updates. Since her paper is due in a month, she decides to end harvesting after 2 weeks. Upon trying to save, Estelle is told that three twitter handles are not valid. She removes them from the list before saving the seeds.
Estelle repeats this for her twitter hashtags, tumblr blogs, and flickr usernames. To enter her twitter hashtags, she chooses the twitter stream seed set type. (For this option, she can’t choose a schedule since streams collect constantly.) For flickr usernames, she chooses to override the defaults and only collect medium size images.
[collection summary screen]
The next day, Estelle receives an email update. The email lists the recent harvesting jobs, whether they were successful, any informational or warning messages, and a summary of the number of items that were published.
After a few days, Estelle wants to address the warning she received that one of her twitter handles is no longer valid (and that this a problem that she can fix), and dig into the collection statistics. She logs into SFM and selects her collection.
First, Estelle decides to remove the errant twitter handle. She selects the twitter user timeline seed set, removes the handle, and saves. When saving, she could have provided a comment, but chose not to. She notices that there is now a log entry for the seed set recording that the handle had been removed.
Second, Estelle navigates to the collection statistics section for the collection. While she could have limited her report by last harvest, last day, last week, or last month, Estelle chooses to get the number of items in the entire collection. She is presented with counts of the number of items that have been harvested (tweets, blog posts, flickr photos, images, web pages, etc.).
After a week, Estelle determines that she has collected enough photos from flickr. She returns to the list of seed sets, chooses the flickr usernames seed set and selects the option to disable collection. Before saving, Estelle has an option to provide a comment on the change she is making, but chooses not to enter anything. After saving, Estelle notices that there is a new entry in the seed set history recording the action she had just taken.
After 2 weeks, Estelle receives an email notifying her that the other seed sets were no longer being collected.
Ready, to analyze the data for her paper, Estelle logs into SFM. Rather than export the data to analyze it outside of SFM, she decides it will be easiest to analyze by browsing the data from within SFM. While browsing, she can navigate through and view a rendering of the harvested social media. The rendering is not true to the original social media websites, but allows Estelle to view the data, including additional collected resources such as images and video.
Completed with her paper, Estelle does not visit the collection again.
Event capture
Event Capture User Story
Georgia is a faculty member at GW and studies the role of NGOs in natural disasters. When the Nepal earthquakes occurred in April 2015, she was interested to harvest social media so that she could later analyze communication about the disaster occurring in these networks. The day of the earthquake, she started browsing for relevant content on Twitter, Tumblr, and Flickr, among other social media platforms.
Georgia has used Social Feed Manager before. She goes to its web page and logs in with her university credentials. Georgia and her research assistant are both members of the same group so that both can work on and access her collections. She creates a new collection for this event, calling it “Nepal Earthquakes”.
She creates a seed set for twitter user timelines and pastes in a list of handles belonging to NGOs she knows to be active in these events, from her previous work. She accepts all of the default options, but opts to collect all related resources including images, videos, and web pages. Upon saving she is informed that the seed set has been created and that all usernames are valid.
Because she is studying communication about/with NGOs, she also wants mentions of those handles. She creates a seed set for twitter stream, understanding that it will allow her to capture mentions and pastes in the same list of handles.
Next, she creates a seed set for twitter stream and pastes in a series of hashtags she has gathered from browsing Twitter earlier. Her list includes #nepal, #nepalearthquake, #nepalquake, #nepal, #nepalquakerelief, nepal. After entering these, she sees confirmation that the tweets are being gathered.
She also wants tweets that appeared before she was able to log into SFM and begin creating her collection. She selects twitter search. The screen has a reminder that it can only go back approximately 7 days, but since the first earthquake was yesterday, she is fine with that. She enters her same set of hashtags from the stream seed set. Also, since the search is meant to only be a temporary approach, she sets it to stop collecting after a week.
Tumblr also has content that Georgia would like to analyze. As with Twitter, she has a list of blogs and tags she would like to retrieve. She creates a seed set of blogs by NGOs by going to tumblr blogs and pasting in the list of blog names (e.g. doctorswithoutborders, oxfam).
Next, she goes to tumblr tags and pastes in a list of tags that she has seen used on Tumblr. These include #nepalearthquakerelief, #nepal earthquake, (#nepal AND #earthquake).
Finally, Georgia would like to capture some photos from Flickr posted by NGOs. To cast a wide net, she creates flickr usernames, flickr tags, and flickr search seed sets. For her purposes, thumbnail and medium size photos are adequate.
She logs out of Social Feed Manager. Georgia is aware that this event is developing and changing rapidly, so she wants to keep an eye on what is being retrieved. Later in the day, she logs in to see what has been captured so far. She goes to the page where she can see the available datasets and stats about her seed sets. She checks the number of tweets that have been harvested for each of her handles, the number of tweets retrieved in the stream and historical search, the number of blog posts for each of the Tumblr blogs, the number of blog posts for each of the Tumblr tag searches, and the photos captured for each of her Flickr seed sets. She is glad to see that all of them have collected at least something so far. She requests a CSV extract of the containing tweets with the #nepal and #nepalearthquake hashtags. Georgia receives an email when the extract is ready. She retrieves the extract and browses through it to look for additional handles and hashtags.
There were new earthquakes occurring daily. As the Nepalese communities dealt with the catastrophe, tourists and visitors start reporting out, and organizations from outside Nepal began to get involved in providing aid, new hashtags and keywords emerge. Georgia notices this through her browsing of the datasets as well as the native platforms. She pays particular attention to the suggestions and trends as she searches the web interface. She then logs back into Social Feed Manager and adds those hashtags, users, and blogs. Georgia notes that a log message is created for each of her changes.
A month after the event occurred, Georgia decides that she has enough data for her project. She logs into Social Feed Manager, turns off the collecting for the whole collection.
Georgia would like to export the entire dataset for the collected Twitter, Flickr, and Tumblr data. This includes CSV extracts of all of the social media data, as well as all images. (Collected web pages, video, and audio are not available for export). She requests the export and receives an email notification when it is ready. When she views the export listing, she realizes that there are too many files for her to download manually. While she is tempted to try to write a script to batch the download, Georgia decides to avail herself of the option to contact the SFM team for assistance. She provides them with an external hard drive onto which they load the dataset.
After the data delivery, she no longer accesses the collection.
Archivist
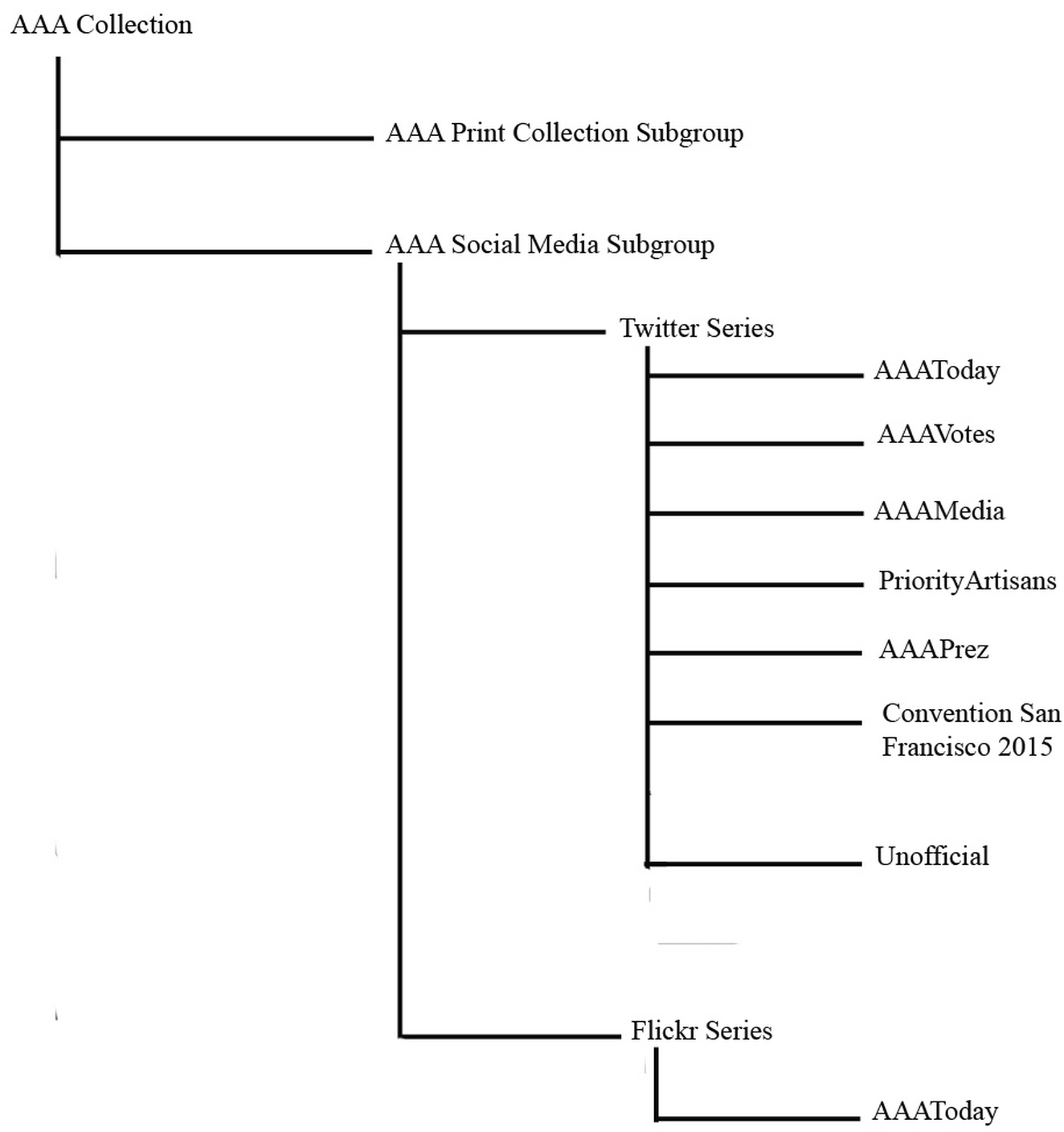
Owen is an archivist responsible for papers of an organization called the American Association of Artisans (AAA) that has been donated to Gelman Library. He becomes aware that they have a social media presence that includes six Twitter handles and a Flickr handle and wants to collect them for permanent retention.
Owen starts by modifying the written policy that covers the AAA Collection. This may be a Deed of Gift or a collecting policy. In it he describes the approach for collecting the social media content.
Owen already has an SFM account associated with the Special Collection Research Center’s group account. He logs in with his university credentials and chooses to create a new collection. Owen is prompted for a collection name and enters “AAA Social Media Collection”. He also enters collection description before being presented with a message that the collection has been created.
Owen creates a seed set for Twitter. He names it Twitter instead of accepting the default name. He adds his six handles. Owen wants to be able to track retweet and favorite counts, so he chooses to collect full harvests (instead of the default of differential harvests). Since he is collecting full harvesting and does not expect the twitter accounts to be too active, he changes the harvest schedule to once every 2 weeks. In addition, he opts to not collect any linked resources and removes the default end date for harvesting so that tweets are collected in perpetuity. He then saves the seeds.
Owen creates a second Twitter user timeline seed set for unofficial handles, in this case to harvest Tweets from personal handles of staff and executives of the AAA. There are 95 seeds that fit this criteria, and he expects he will add more.
AAA has a Flickr account for which Owen creates a flickr username seed set. He chooses to collect new thumbnail and original size images once every 2 weeks (hence a differential harvest). He saves the seed.
Lastly, Owen creates a tumblr blog seed set for AAA’s blog. Similar to Twitter, Owen is interested in how reblogs and notes change over time so he chooses to do a full harvest every 2 weeks. Since related resources are key for blogs, Owen collects all related resources. He saves the seed.
Owen receives an email at the end of the week informing him that the first week’s harvest has taken place. He logs in to see how the harvest is going. He looks at some analytics on what has been harvested so far, and discovers that 2 of the Twitter handles are far less active than the other 6, and those 2 handles have received no user mentions. He looks at the seed set for unofficial handles and finds that 11 of the 95 seeds have very low activity. He decides to keep all 6 official handles but deletes the 11 low-activity unofficial seeds. The Tumblr seed set is entirely inactive, so he decides to deactivate that entire seed set.
After 6 months, Owen decides it is time to create a finding aid for the AAA Social Media Collection. Before creating the finding aid, he analyzes the collection by looking at the collection statistics and browsing the harvested social media.
He creates a template in Archivists Toolkit (AT) and fills in the required fields as follows:
Level: Subgroup
Since there is already a collection of print materials in AT classified as a record group, the American Association of Artisans Social Media Collection is listed as a subgroup. This allows for series to exist for each seed set.
- Title: American Association of Artisans Social Media Collection
- Date Expression: February 20, 2013-July 3, 2015 (reflecting the date of the first and last posts in the harvest)
- Resource Identifier: Subgroup 1
- Extent: 15000 items
- Arrangement Note: [Description of how posts are grouped, perhaps? By WARC/harvest, seed, than seed set]
- Historical Biographical Note: A listing of all seed sets.
Owen then creates two series as children of the American Association of Artisans Social Media Collection.
Level: Series
- Title: American Association of Artisans Flickr
- Date Expression: March 3, 2013-June 19, 2015 (reflecting the date of the first and last Tweets in the harvest)
- Resource Identifier: Subgroup 1 Series 1
- Extent: 400 items
- Arrangement Note: [Description of how posts are grouped, perhaps? By WARC/harvest, seed, than seed set]
- Historical Biographical Note: An explanation of what Flickr is and how it was used. A listing of all seeds.
Level: Series
- Title: American Association of Artisans Twitter
- Date Expression: February 20, 2013-July 3, 2015 (reflecting the date of the first and last Tweets in the harvest)
- Resource Identifier: Subgroup 1 Series 2
- Extent: 4600 items
- Arrangement Note: [Description of how posts are grouped, perhaps? By WARC/harvest, seed, than seed set]
- Historical Biographical Note: An explanation of what Twitter is and how it was used.
- Scope and Content: A listing of all seeds.
Below the Twitter series, there are seven subseries, including five from official AAA handles, one from a stream search (Convention 2015) and one subseries containing nearly 100 handles (Unofficial).
Level: Subseries
- Title: AAAToday
- Date Expression: February 22, 2013-July 3, 2015 (reflecting the date of the first and last Tweets in the harvest)
- Resource Identifier: Subgroup 1 Series 2 Subseries 1
- Extent: 1000 items
- Arrangement Note: [Description of how posts are grouped, perhaps? By WARC/harvest, seed, than seed set?]
- Historical Biographical Note: Bio/line from handle. If multiple versions exist [?]
- Scope and Content Note: This includes analysis of the collection; possibly including: hashtags, significant events, word cloud analysis, common user mentions, inclusion of images or urls.
Level: Subseries
- Title: Unofficial
- Date Expression: February 22, 2013-July 3, 2015 (reflecting the date of the first and last Tweets in the harvest)
- Resource Identifier: Subgroup 1 Series 2 Subseries 7
- Extent: 10000 items
- Arrangement Note: [Description of how posts are grouped, perhaps? By WARC/harvest, seed, than seed set?]
- Historical Biographical Note: Too many to include? Perhaps a note about what criteria were considered when choosing these handles for harvest, and a listing of handles?
- Scope and Content Note: This includes analysis of the collection; possibly including: hashtags, significant events, word cloud analysis, common user mentions, inclusion of images or urls.
Where appropriate, Owen provides a link to the collection or seed set in SFM.
He decides to update the description every 6 months.
Visualization of Arrangement
Future researcher
Future researcher #1
- Locates relevant collection via searching seeds
- Some initial analysis of the collection within SFM
- Selects dataset to export
Edward is a business student conducting research on the marketing of Animal Planet’s Finding Bigfoot television program on social media. He learns from a reference librarian that GW Libraries collects social media and is directed to SFM.
After logging in with his university credentials, Edward wants to determine if any useful social media has been collected. He can search/browse by collection or seeds (twitter handles, twitter hashtag, tumblr blog, or flickr username) or perform a full-text search (only of collections that have been selected for full-text indexing). Edward knows that Finding Bigfoot encourages the use of the #FindingBigfoot hashtag, so performs a search on it. From the results he learns that #FindingBigfoot was one of the seeds collected as part of the BFRO collection. It has been collected on a monthly basis since 2011 (season 1!).
Edward is interested in the entire BFRO collection, so chooses to explore the entire collection. He examines the various seed sets, including the logs of how the sets have changed over time.
To determine the effectiveness of the marketing campaign by Animal Planet, Edward focuses on a subset of related seeds within the BFRO collection (Official Animal Planet’s twitter handles, tumblr blogs or flickr accounts,etc). He defines a dataset scoped by this subset of seeds and a time range of interest and requests an export as Excel.
When SFM has completed creating his export, SFM sends Edward a notification that his export is available. Edward logs into SFM and navigates to his list of exports. He sees that the new export is of a sufficiently small size that it may be downloaded via the browser. He downloads the individual files to his computer.
Opening the files with Excel, Edward analyzes viewers’ responses to the advertising/marketing media posts as indicated by comments, reposts, retweets, and the like. Edward also compares the viewer’s response on different social media platforms to recognize which media platform is most frequented by viewers or which media platform was most effective for marketing/advertisement by Animal Planet.
Future researcher #2
- Locates relevant collections via full-text search on collections content
- Beyond initial browsing, researcher does most analysis using exports
Viraj is a Masters student in Engineering Management with a concentration in Crisis, Emergency and Risk Management. He is researching social media’s role during natural disaster events. He learns from a reference librarian that GW Libraries collects social media and is directed to SFM.
Viraj logs into SFM with his university credentials and performs a full-text search on “earthquake”, a full-text search on “hurricane”, and a full-text search on “tsunami”. The “earthquake” full-text query results indicate that SFM contains three collections with many occurrences of the word “earthquake” in social media post text: a collection themed around the 2015 Nepal Earthquake; a collection themed around the 2016 Foggy Bottom Earthquake; and the twitter sample stream collection. There are other collections containing these words, but at a much lower frequency. The titles of the first two collections indicate to Viraj that these are likely to be focused on his area of interest, while the twitter sample stream collection seems to promise a coverage of a broader number of events, though less complete.
For the 2015 Nepal Earthquake collection and the 2016 Foggy Bottom Earthquake, Viraj determines that he would like to export the entire collections. For the twitter sample stream collection, Viraj identifies a set of hashtags to which to limit the export. Outside of SFM, he analyzes these social media datasets to compare and contrast social media use around these two similar events, focusing on social media’s role in the emergency management of each event.
Collection review
The GWU SFM team holds its periodic collection review. They consider a list of five collections that are not marked as for permanent retention and are no longer actively harvesting or have been harvesting for a long period of time.
The first collection has been harvesting for almost 2 years. However, they are aware that the researcher is performing a long-term study and so ignore this collection.
The second collection has been harvesting for a year and a half. Not familiar with the collection, Melvin, the representative from GWU’s Special Collection Research Center (SCRC) contacts the researcher to ask about the research status. Melvin learns that the researcher has completed her research and no longer requires the collection. Melvin determines that the collection is of sufficient interest that SCRC would like to adopt the collection. He logs into SFM (Melvin is an administrative user) and changes the ownership of the collection to the SCRC group, marks the collection as for permanent retention, and records a note explaining the decision to adopt the collection. He notices that the ownership change, the change of archival status, and the note appears in the log for the collection.
The third collection has not been harvested for 3 months. Again, Melvin contacts the researcher. The researcher states that she is still analyzing the results so Melvin takes no further action on the collection.
The fourth collection has not been harvested for 5 months. When Melvin attempts to contact the researcher, he learns that she has graduated. The collection is not within a collecting area for SCRC. Melvin logs into SFM and deletes the collection, providing a note explaining his action. The collection is marked as deleted, data is deleted from other SFM services, and data files are deleted. The record for the collection is still available to SFM administrators, but not other users.
The fifth collection has not been harvested for 5 months as well. Melvin learns from the researcher that the collection will be used for a class that she periodically teaches. Melvin logs into SFM, marks the collection as for permanent retention and records a note explaining the decision to mark it as as such. Marvin also decides for the collection to be fulltext indexed.