Under the wire, version 1.4 is our 8th release of SFM for 2016!
In this post, I’m going to discuss the work in this release to provide a README file accompanying data exports and to prevent harvest congestion. I will then highlight a few additional noteworthy enhancements for SFM users.
Recording provenance metadata has been an important focus of SFM. In order to meet the needs of both social media researchers and archivists/librarians, being able to document how and why a collection was built is essential. (Check out our Provenance of a Tweet working paper for more detail.) In support of this, we’ve taken a first cut at generating a README file with every export. The README includes information on the exported dataset and the collection. Here’s a (slightly truncated) example:
This is an export created with Social Feed Manager.
EXPORT INFORMATION
Selected seeds: All seeds
Export id: 4073efbf9d8c4a2282eff3f0e6803519
Export type: twitter_user_timeline
Format: Excel (XLSX)
Export completed: Dec. 21, 2016, 8:16:08 a.m. EST
Deduplicate: No
COLLECTION INFORMATION
Collection name: Administration officials user timelines
Collection id: 5cea0641395a4c46b63361712423506e
Collection set: Trump Administration (collection set id 6dcb8592d16b46a3a2fe9b377593ffcb)
Harvest type: Twitter user timeline
Collection description: From https://en.wikipedia.org/wiki/Cabinet_of_Donald_Trump
Schedule: Every week
Harvest options:
User images: No
Incremental: Yes
Web resources: No
Media: Yes
Seeds:
* Token: RepMickMulvaney; Uid: 240385577 - Active
* Token: RepRyanZinke; Uid: 2953494478 - Active
* Token: RyanZinke; Uid: 1906282568 - Active
* Token: GovernorPerry; Uid: 18906561 - Active
* Token: RexTillerson2; Uid: 808208092018176000 - Inactive
* Token: SenatorSessions; Uid: 47975734 - Active
* Token: jeffsessions; Uid: 986781648 - Active
* Token: mike_pence; Uid: 22203756 - Active
* Token: realDonaldTrump; Uid: 25073877 - Active
Change log:
Change to Token: RepMickMulvaney; Uid: 240385577 (seed) on Dec. 17, 2016, 11:53:43 a.m. EST by system:
* uid: "blank" changed to "240385577"
Note: Changed uid based on information from harvester from harvest 332d899bb5b942fc8c363c236eada2bf
Change to Administration officials user timelines (collection) on Dec. 17, 2016, 11:53:08 a.m. EST by justinlittman:
* is_active: "False" changed to "True"
Change to Token: RepMickMulvaney (seed) on Dec. 17, 2016, 11:53:06 a.m. EST by justinlittman:
* token: "blank" changed to "RepMickMulvaney"
* is_active: "blank" changed to "True"
Change to Administration officials user timelines (collection) on Dec. 17, 2016, 11:52:56 a.m. EST by justinlittman:
* is_active: "True" changed to "False"
Change to Token: RyanZinke; Uid: 1906282568 (seed) on Dec. 15, 2016, 11:14:30 a.m. EST by system:
* uid: "blank" changed to "1906282568"
Note: Changed uid based on information from harvester from harvest 2d18e8b3b8ae408a8e3147f84810773e
Change to Token: RepRyanZinke; Uid: 2953494478 (seed) on Dec. 15, 2016, 11:14:30 a.m. EST by system:
* uid: "blank" changed to "2953494478"
Note: Changed uid based on information from harvester from harvest 2d18e8b3b8ae408a8e3147f84810773e
Change to Administration officials user timelines (collection) on Nov. 21, 2016, 11:26:07 a.m. EST by justinlittman:
* description: "blank" changed to "From https://en.wikipedia.org/wiki/Cabinet_of_Donald_Trump"
Change to Token: mike_pence (seed) on Nov. 21, 2016, 11:23:33 a.m. EST by justinlittman:
* token: "blank" changed to "mike_pence"
* is_active: "blank" changed to "True"
Change to Token: realDonaldTrump (seed) on Nov. 21, 2016, 11:21:58 a.m. EST by justinlittman:
* token: "blank" changed to "realDonaldTrump"
* is_active: "blank" changed to "True"
Change to Administration officials user timelines (collection) on Nov. 21, 2016, 11:21:41 a.m. EST by justinlittman:
* credential: "blank" changed to "justinlittman's twitter credential"
* harvest_type: "blank" changed to "twitter_user_timeline"
* name: "blank" changed to "Administration officials user timelines"
* collection_set: "blank" changed to "Trump Administration"
* is_active: "blank" changed to "False"
* schedule_minutes: "blank" changed to "10080"
* harvest_options: "blank" changed to "{"user_images": false, "media": true, "incremental": true, "web_resources": false}"
Created on Dec. 21, 2016, 8:16:08 a.m. EST
Feedback on the README would be appreciated: @SocialFeedMgr or sfm@gwu.edu.
One of the challenges that we have encountered is how to prevent harvester congestion, in particular for the Twitter REST harvester. Harvesting congestion occurs when harvest requests are queued up waiting for a harvester to become available. If the queue is too long, it means that harvesting won’t be performed in a timely fashion and the harvest queue may grow faster than the harvests are being performed. There are a number of reasons that this may occur:
- There aren’t enough harvesters running. This is easily resolved by scaling the number of harvesters.
- Schedules for a collection are too short, such that even without congestion, previous harvests don’t complete before a new harvest is scheduled.
- Harvests take an unexpectedly long time to complete because they have to pause due to Twitter’s rate limit. This can be because a single harvest has a large number of seeds or because there are multiple harvests being performed concurrently that are using the same API keys.
Rather than over-engineer, we implemented some simple solutions to avoid harvester congestion:
- We now recommend scaling the Twitter REST harvester by default.
- We provide monitoring of harvesters and queue lengths.
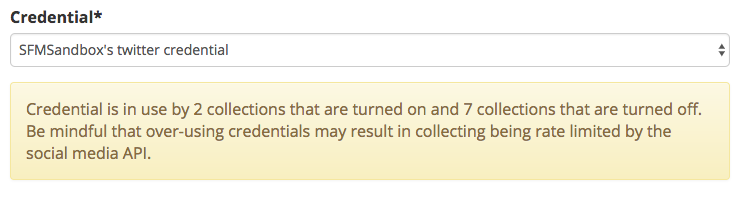
- When selecting Twitter credentials for a collection, users are notified of the number of other collections that are also using those credentials.
- If the scheduler attempts to request another harvest, but the previous harvest isn’t completed, the new harvest will be skipped. Users and admins will be notified so that they can investigate further.

We will continue to hammer on harvester congestion, as scaling the number of collections and seeds within a collection is one of the key goals of SFM to support researchers and archivists.
Two additional enhancements make SFM easier to use. Links to the social media websites are now provided for seeds. This was requested to help with curating seed lists.
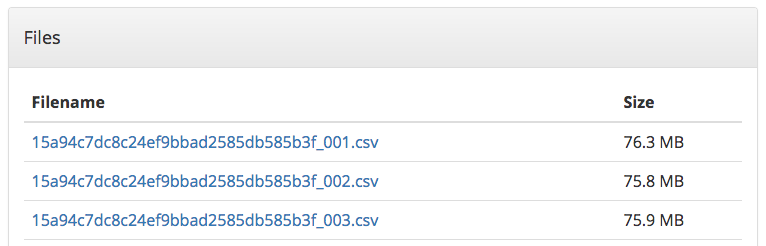
To assist with users trying to export largish datasets, exports can be now be segmented into multiple files. The number of items to include in each export file can be selected when requesting the harvest.

Special thanks to our grad student programmers, Victor Tan and Aditya Dharne, who made this release possible (despite final exams!).