Editor’s note: In June, we published the report Social Feed Manager: Guide for Building Social Media Archives, written by Christopher Prom of the University of Illinois with support from our grant from NHPRC. To highlight this work and the insights it provides to the community, we’re sharing excerpts of the report as blog posts. This is the first in a series of posts we’re calling “SFM for Archivists”.
Institution-Led Collecting
As noted in SFM’s Collection Development Guidelines, archivists and curators may wish to use Social Feed Manager to collect social media collections that become part of their long-term holdings. While this was not the original purpose of the tool in its early versions, and while it raises potential ethical and legal issues that will need to be managed in a policy framework, this blog post outlines a few potential institution-led collecting efforts that repositories may wish to consider.
Capturing Institution-Related Materials
Institutional archives, such as a government, university and business archives, bear a responsibility to preserve records generated by their parent organization. While social media collecting is likely to be a new area for most repositories, SFM’s twitter timeline harvest feature could be used to establish a one time or incrementally-updated feed of new tweets from one of more user accounts that are managed by the parent organization. The following possibilities suggest themselves:
- Using one collection set to collect an organization’s records: In the case of smaller organizations with relatively few social media records, the organization might establish a collection set with a title like “Organization Name Social Media Records”. Within this collection set, three collections could be established, one for twitter user timelines, one for flickr posts, and one for tumblr blogs. Within each collection, all streams across the organization could be listed, as shown in below.
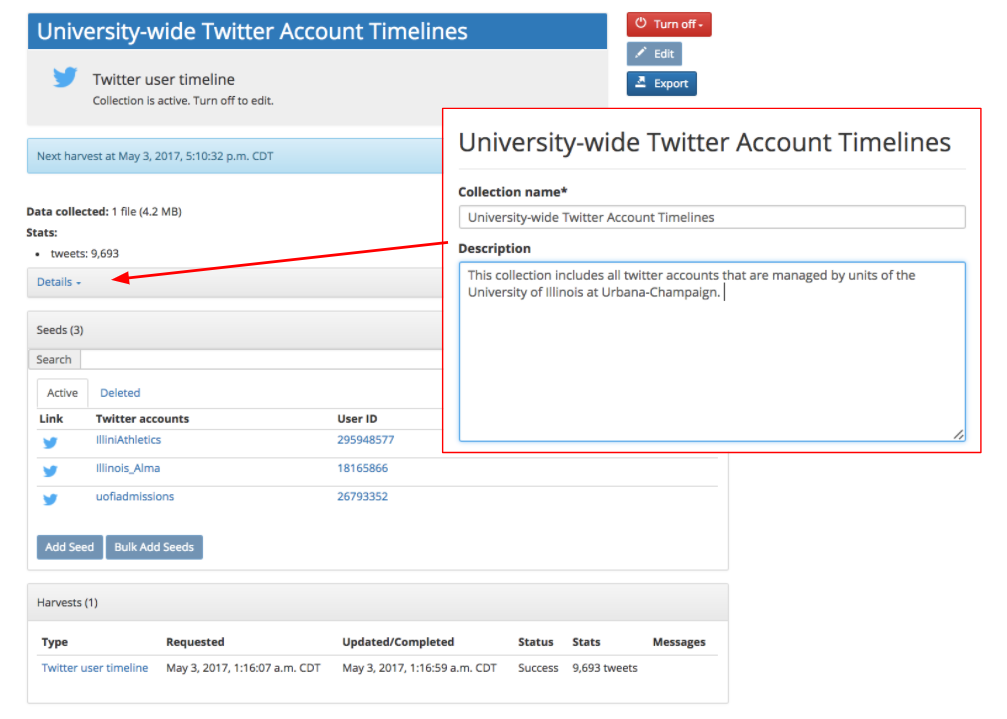
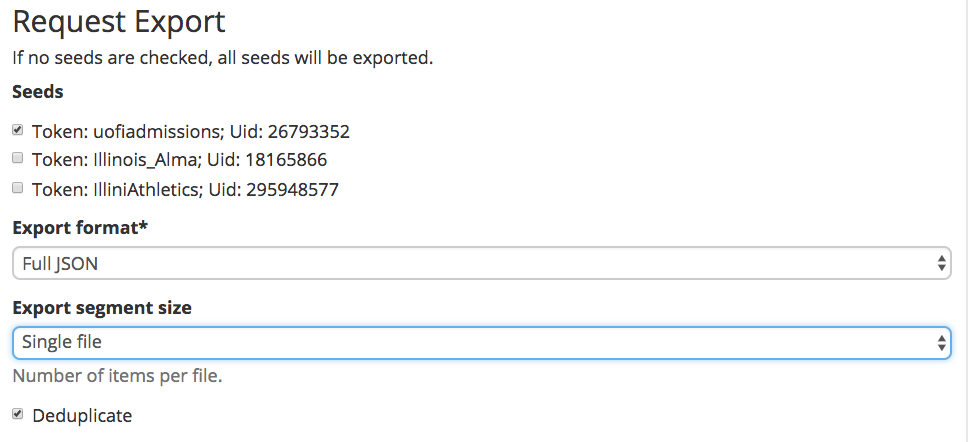
The advantage to this approach lies in the fact it’s relatively low-effort and low-maintenance: As new accounts are identified, they are simply added to the seed lists. And (assuming none of the account tweets more than 3,000 times per month), harvests could be run infrequently, resulting in a relatively low number of WARCs to be preserved. However, a few potential drawbacks obtain. Notably, data from multiple twitter accounts will be included in each WARC. When staff members export data from SFM, they should consider how to integrate the exported data into a classification system and repository infrastructure. As a low-effort approach, the entire collection set could be packaged and preserved as a discrete digital object and described as a collection in a collection management system. If this is done, it will be much more difficult to provide some kind of series breakdown or to separate records by provenance, unless staff members create separate exports. If, on the other hand, an archives wants to separately classify records by accounts, it could filter exports by seed, as demonstrated in the figure below. This method would only be suitable in cases where web resources have not been harvested, since linked and embedded resources are not currently included in the exported dataset. Regardless, the “preservation by export” method would sacrifice some of the metadata that SFM keeps regarding its actions, as discussed in more detail below.
-
Organization by records creator: As a counterpoint, an archives may wish to establish separate collections for each account or for each records creating entity within an organization. Obviously, this would require more upfront effort, but collections could be described with more granularity within SFM, before being copied into the preservation repository and described in an archival management system. As new materials are captured in the system, the new harvests could be added as accruals, within the parent folder. This approach also holds a few potential downsides. In particular, collecting organizations should note that each collection will hold objects of only one type. If a unit uses all three channels (Twitter, Tumblr, and Flickr), and an archives wants to organize records sharing this provenance, they would need to undertake some external packaging and addition description, before ingesting the files into a preservation repository.
-
Function-driven collecting: This is a hybrid approach, combining some of the features of the others just described. If an institution uses a documentation strategies approach, accounts relating to public relations could be grouped together, accounts from academic departments in another, and institutionally affiliated student organization in a third. (In the case of student organization, archivists should gain permission, preferably written via a deed of gift or other instrument, from a representative of the student organization before beginning harvesting, since it is unlikely that the university or college will own copyright on the harvested data.) The provisos mentioned above should be borne in mind, since the specific ways collection sets and collections are established will affect export, packaging, description, and preservation potentials that might be afforded to them outside of SFM.
Documenting Events
Many repositories may wish to harvest materials documenting particular events or controversies, particularly if they expect that their future user community will have an interest in the event. While the particular events being documented might range from the mundane (a graduation ceremony, perhaps) to the controversial (a violent act or protest), SFM’s twitter search and filter harvests provide tools that archivists can use to capture data for future research and preservation.
As a relatively simple example, the University of Illinois Archives collected records for a Science March, using the twitter search harvester. We knew about relevant accounts and hashtags ahead of time, and by carefully constructing a search string, we gathered many records including some tweets and web resources that had been posted prior to the event.
This may seem like a subtle point, but the ‘recordness’ of this collection lies in the University of Illinois Archives’ choice to collect the records, not in the activity of some other campus unit. Since the record of this event was generated by the archives, it will be added to our collection of archives-generated social media records. We plan to create one record in our collection database to describe all of the social media records gathered by the Archives. Each harvest project will be described at the file level; if the collection grows over time, files could be grouped at a series level by topic or some other criteria. We plan to publish datasets through our digital library and also possibly through the DocNow Catalog. GW Libraries has also provided some good thoughts about releasing datasets through their blog.
Collecting Topical or Subject-Based Records
Archives, of course, tend to have particular subject strengths, often reflecting the interests or characteristics of the parent institution. While considerable discretion is in order, an archives may wish to gather records that support future research in a general area. In fact, GW Libraries uses the tool in just this way, as the described in Justin Littman’s post about a single day of collection activity. At that time, GW Libraries was building collections about Congress, Healthcare, “Make America Great Again,” the Donald Trump Administration, opposition to the Administration, and several topics of interest to GW faculty. Obviously, subject-based collection efforts could become rather amorphous or result in huge datasets, if not properly scoped. Nevertheless, this strategy might be employed in a similar way to event-based collecting, with one difference: It typically would make most sense to employ a twitter filter harvest rather than a search harvest, because the appropriate search terms are known ahead of time. Otherwise, the same considerations mentioned for event collecting apply to topical collecting.
Ideally, collection efforts for subject or topical collections will be coordinated among multiple partners, as more archives begin using SFM. For example, GW Libraries is already collecting all tweets by Illinois members of the US House of Representatives and Senate, as they are for all states. State repositories may have an interest in developing complementary (e.g. state-level) collections to complement the larger datasets—for example tweets about or in response to politicians representing the states, not just tweets from the representatives and senators. In this sense, ‘person-based’ collecting could be seen as a variant of subject-based collecting, where you are more interested in tweets about a person, than by that person.
Facilitating Records and Information Compliance
SFM could be used as a cost effective means to copy and store social media posts sent by state agencies, public universities, or other organizations that have a need to ensure compliance with legal requirements or records management imperatives. By configuring one or more account timeline harvests, and organization would keep a potentially-complete record of all activity undertaken by the account. The institution would need to define policies for the retention and long term disposition of the materials, perhaps in conjunction with an archivist or member of legal counsel, and it is likely that some of the records, if the not the entire stream of activity, might have long term administrative or research value to the institution.
If an institution is considering the use of using SFM for records management purposes, staff members should bear in mind that SFM may not capture everything issued by a particular account or related to a particular search. It will certainly capture most traffic, but 100% capture is not guaranteed. This is less a limitation of SFM than of the free APIs that SFM uses. They simply do not guarantee complete coverage. If the collecting organization wishes to ensure the highest levels of compliance and capture, staff will need to contract with an external service, such as ArchiveSocial or DiscoverText. Nevertheless, SFM may have a records management role to play in cases where records are being captured less for legal reasons than historical or administrative ones, but where some compliance needs also exists.