Editor’s note: In June, we published the report Social Feed Manager: Guide for Building Social Media Archives, written by Christopher Prom of the University of Illinois with support from our grant from NHPRC. To highlight this work and the insights it provides to the community, we’re sharing excerpts of the report as blog posts. This is the second in a series of posts we’re calling “SFM for Archivists”.
Shaping Local Services
Once archival staff understand SFM’s basic functions, they can make decisions about how the tool will be used. Some considerations are worth extra attention by repository staff before they or other users begin establishing collection sets, collections, and seeds, particularly if the records will be saved for future research value in an archival or special collections library.
Users should note, for instance, that SFM is structured with a relatively flat data model, whereby a collection belongs to only one collection set. It is not possible to define subcollections or otherwise differentiate or group seeds within a collection; nor can a collection be shared across two collection sets. For an archivist who may be accustomed to classifying materials with increasing granularity, or in providing cross-cutting access points, these limits should be borne in mind.
After all, SFM’s main purpose is to capture records, not to describe them. Nor it is intended to help repositories develop a classification structure that relates collections to each other or to other records that the same person or organization might have created. Both of these tasks should be completed in external systems, such as a repository’s collection management software, not inside SFM. Yet the collecting organization will reap long-term dividends by using the descriptive fields that it makes available. Users should pay particular attention to the ways in which they organize, name, and describe collection sets and collections. Since people with access to SFM’s user interface can generate collection exports (but not collection set exports), archivists will want to establish collections with an eye to how they will be described and preserved.
For instance, an archives might establish a collection set to harvest the timelines of accounts managed by the institution, then group seeds in collections thereunder, to reflect a shared provenance. Materials harvested under that collection set could be be described and packaged and described in aggregate reflecting their provenance. The exported social media data for a collection would compose a single archival information packet, one that could be uploaded to a local digital preservation repository. (SFM version 1.8 and higher support moving collections to other collection sets, so related collections could be grouped after the fact into a single collection set, then exported for external preservation, if a different organizational method is chosen by the repository.)
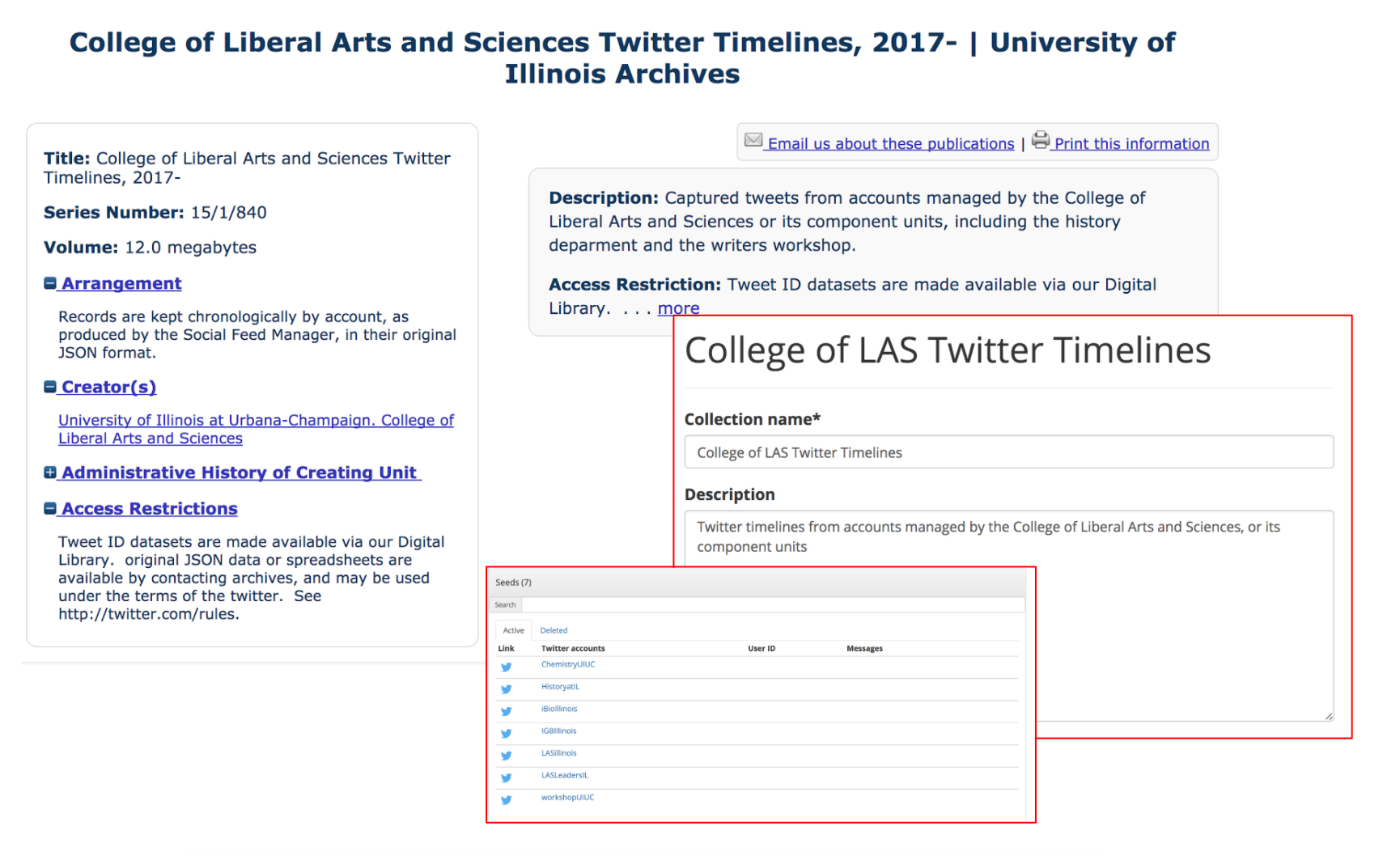
Consider the example of an archival repository that has previously arranged the files of a campus unit or department, say the College of Liberal Arts and Sciences, within a single collection description, with links to particular record series that were generated by the College. The archives has previously developed a single authority record describing the College, and has linked that authority record to series level records descriptions (such as the Dean’s Subject File, Executive Committee Minutes, Press Releases, Personnel Files; or the Subject Files of various departments found in the College). Social media records are simply another record of the College’s activities. The archives could then group social media feeds for individual units in the college as a single collection, adding a seed for each twitter account managed by the college or one of its subunits. This would aggregate similar records together and would allow them to be exported as a single archival information packet, one that could then be described in an archival management system just like any other record of the college’s activities. Figure sixteen shows a sample descriptive record for a packet of such records, as collected by SFM.
The same archives may wish to develop a different implementation model for capturing social media posts by faculty who have agreed to donate their personal timelines to the Archives. In this case, a single collection could be established for each faculty member, in a collection set that is dedicated to Faculty Social Media. That would allow for the export of social media posts by a particular faculty member at some future point in time, in which case they could be integrated into a collection description for that faculty member’s personal and professional papers, including other records such as subject files, correspondence (including email) or whatever other series reflect that faculty member’s activities.
Similar arrangements could be made in the case of student organizations: a parent collection set for social media records from those groups, and collections grouping twitter timelines or search captures related to particular student groups or campus issues.
Yet other options suggest themselves. Since SFM supports the capture of records that support faculty or student research projects, all such projects could be segregated from the collections being generated and gathered (by archives staff) as an institutional record. The faculty and student captures could then be kept only for personal use under research projects, or, if the faculty and students agree, accessioned into the archives and managed under terms that respect the legal and ethical requirements that may pertain.