Editor’s note: In June, we published the report Social Feed Manager: Guide for Building Social Media Archives, written by Christopher Prom of the University of Illinois with support from our grant from NHPRC. To highlight this work and the insights it provides to the community, we’re sharing excerpts of the report as blog posts. This is the fifth in a series of posts we’re calling “SFM for Archivists”.
Data Model Overview and Implications for Preservation
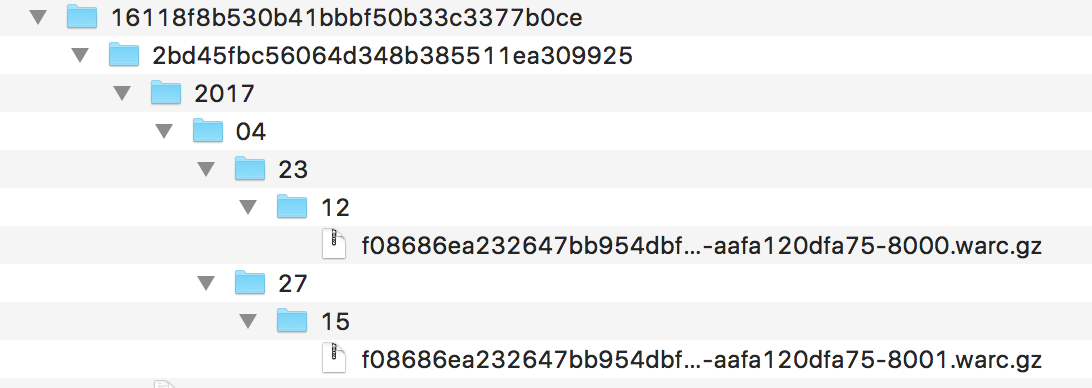
When archivists and repository staff members consider options for the long-term preservation of the data collected by SFM, they should aim to preserve both social media data and metadata about the social media records. The diagram below provides a simplified overview of preservation-relevant data objects managed by the system including both objects managed in the database and in WebArchive (WARC) files:
(Some elements of SFM’s data model, such as user accounts, groups, credentials, and exports, were omitted from the diagram, since they are not immediately relevant to the following discussion.)
Each of the metadata entities shown in the top boxed portion of the entity relationship diagram corresponds to a particular data table in SFM’s database.
The top-level objects managed by SFM are known as collection sets. As the notation illustrates, each collection set may contain one or more collections, and each collection can belong to only one collection set. The nature of each collection (i.e. what has been harvested or will be harvested in the future) is determined by it harvest options and by the list of seeds that have been input for each collection. Each collection can have multiple seeds, but each seed record belongs to only one collection. (If the same seed, e.g., a twitter timeline harvest for the seed @realDonaldTrump, is listed under two different collections, the database would record two different seed records, each with its own unique ID. It should also be noted that the twitter search harvest only allows harvesting from one seed at a time.)
Seeds and Collection Types
In SFM, a ‘seed’ is a harvest pathway: a defined method by which SFM queries an API and by which social media is captured and stored to SFM’s data store. It is a deceptively simple concept.
SFM seeds are both similar to and different from the web harvesting seeds with which archivists may be familiar, such as those entered into Archive-It. They are similar in the sense that the user supplies a designated starting point from which a specific set of resources will be captured. And there is another similarity: the user can define parameters that should be applied to associated harvests. (For example, in Archive-It, the user can specify if the harvester should capture just the seeded page, other pages on the same site, and/or external resources. Similarly, in SFM, the user can specify whether the harvester should capture just the structured data supplied by an API or related resources, such as embedded photos/video or linked webpages.) The difference lies in the fact that SFM seeds do not target public web resources (i.e. web pages and their components). Rather, they aim to capture the output of an API: data that typically undergoes machine processing before being rendered in an interface.
Furthermore, there is another difference: SFM supports several different types of seeds, and each one of them behaves somewhat differently, in accord with the features afforded by the API that it is querying. It is important to note that the seed type is set at at the collection level in the user interface, and that in effect, the seed type is a collection attribute. This means that each collection will comprise a particular type of resource, one that format based. It is not possible, for instance, to combine tumblr blog, flickr posts, and tweets in the same collection. Nor can two different seed types be mixed in one collection; for example a twitter timeline and a twitter search seed cannot be joined side-by-side in the one collection.
Practical Implications
Archivists and other users benefit from understanding SFM’s technical model because it shapes the ways in which they can collect, preserve, and access social media records. For example, the fact that each collection may only comprise seeds of a particular type imposes certain limits on collecting practice. On balance, these limits have more benefits than drawbacks. Not only do they contribute to the tool’s overall ease of use, but they result in the gathering of consistent, orderly, and preservable digital objects. Nevertheless, they must be borne in mind by those using the tool, particularly in cases where there is some expectation that the data will be preserved for its continuing value, not just to serve an immediate research need.
For example, say an archivist would would like to collect tweets, tumblr posts, and flickr gallery images from a person who has public accounts in all three services. Furthermore, assume the collecting organization would like to preserve these outside the system and to group them by their provenance, as the output of that person’s activities and in relation to other digital materials generated by that person. In order to capture these three types of records (tweets, tumblr posts, and flickr images), the archivist will need to establish three separate SFM collections (a twitter timeline harvest, a tumblr blog post harvest, and a flickr user harvest). To group these SFM collections as a preservation object, staff would need to make a choice. They might group them in a single collection set, stating their common relationship by provenance in the note field of the collection set. Or, they might keep them in separate collection sets, then unite them externally when packaging them for deposit in a preservation system. In this case, staff members may need to export three sets of records, package them as a unit, then describe that package and its component parts, if they want to show their relationship to each other as the activities of a single individual.
In other words, decisions made at the collection set and collection level should be taken very carefully. An archives’ staff members should carefully consider how they will shape their collections set and collections (By topic? By provenance? By some other factor?), basing decisions on long-term collecting objectives, descriptive practices, preservation capacities, and other factors they deem most relevant.
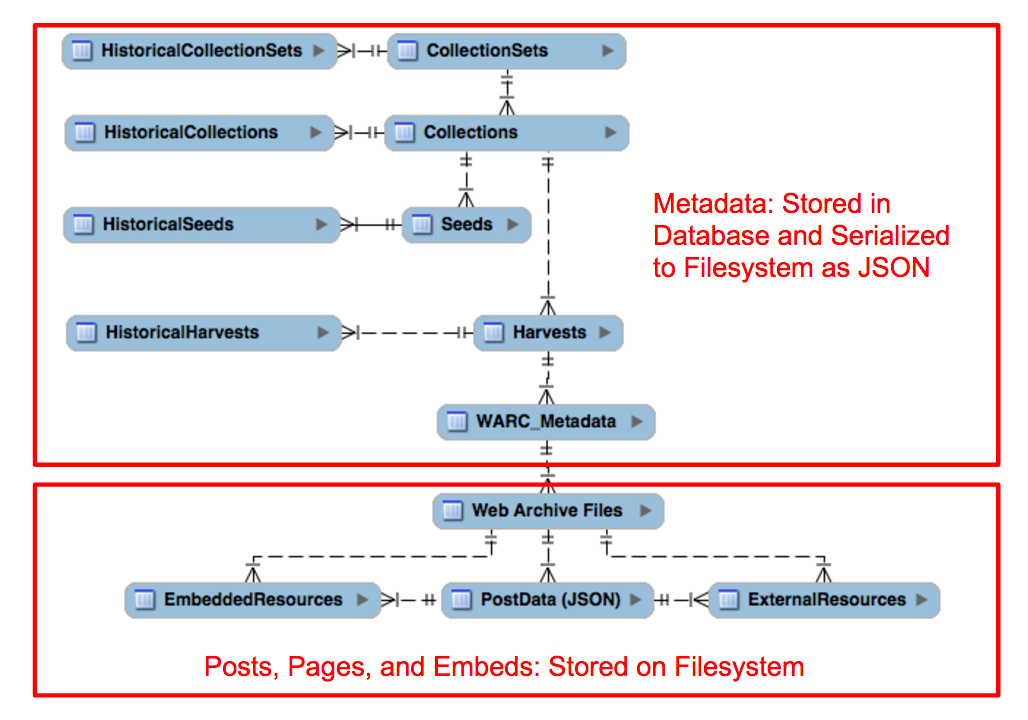
The decision about how to shape collections matters for another reason: Harvest parameters are set at the collection level (as shown below) and are stored in the database as properties of the collection. In practical terms, this means that the harvesting of external objects and the frequency of harvesting are set on a collection basis, and that decisions made here will apply to each of the seeds that compose a collection.
Looking back at the earlier figure showing SFM’s data/object model, each collection record may contain one or more harvests. In essence, a harvest is conducted whenever the SFM application is running and whenever a user or the system initiates a capture, based on the scheduling frequency noted on the collection record. When a harvest begins, SFM’s messaging agent queues and issues request for the seeds that are currently active in that collection. It issues an API call to the social media service provider and copies the response to a WARC file, writing the precise JSON response as supplied by the API, along with the http headers. If the user has configured the collection to harvest web resources (such as embedded files and links to web pages), they are written to a separate WARC file. When harvesting has finished, the series of WARC’s are written to a docker container or the file system (as specified in SFM’s configuration setting.)
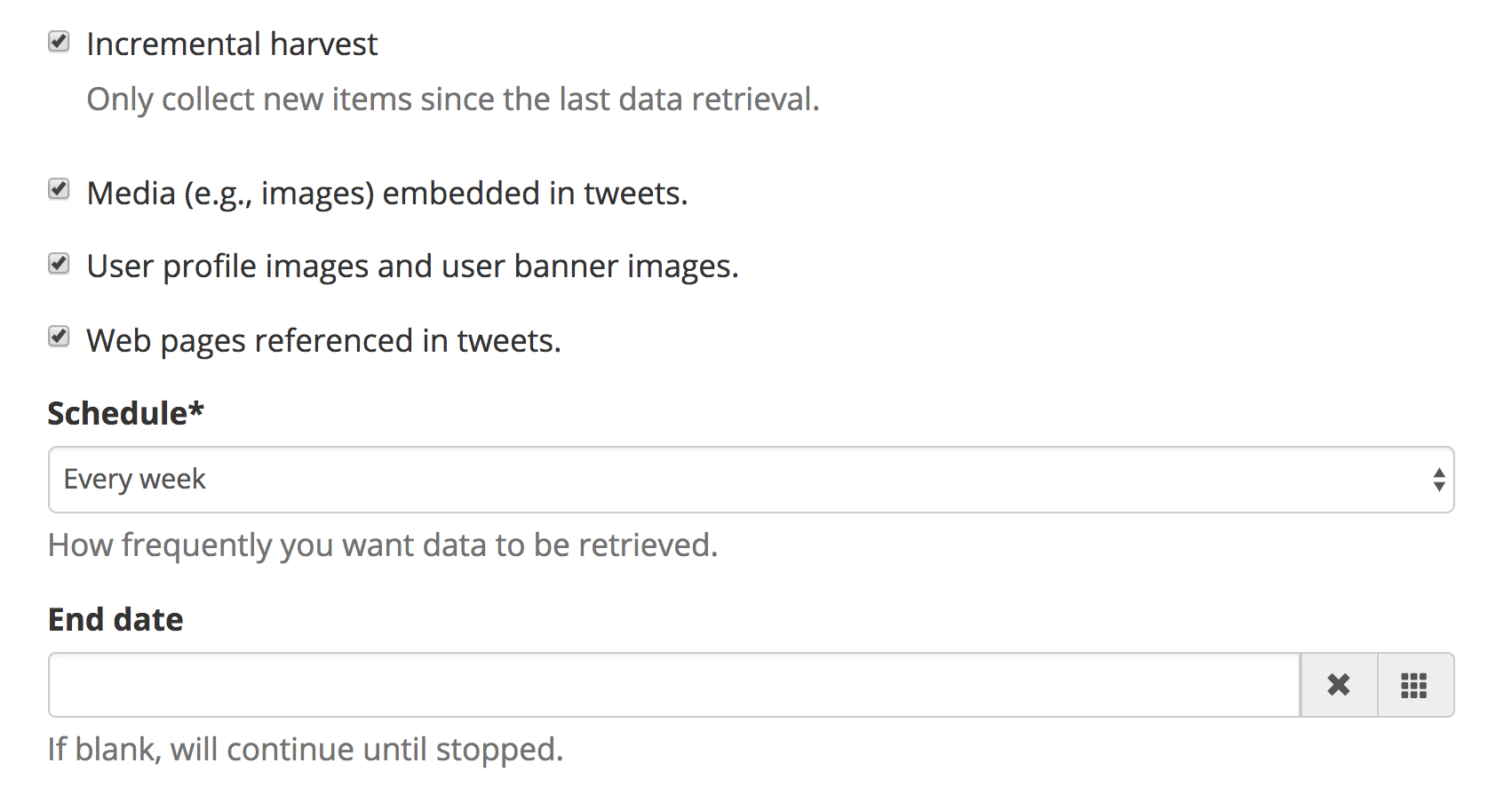
It is critical to understand that for each harvest, the system captures both a WARC file and some metadata about the WARC. Each capture is stored in a very systematic way and with a JSON representation of the metadata that is stored in the database, as shown below.
As additional harvests are completed, the application generates additional WARC files, storing them in a directory structure that reflects the harvest date. Metadata about the WARCs is stored in the database and, on a nightly basis, serialized into the JSON files, as shown in the screenshot above.
In effect, SFM functions like a ‘minimalist repository,’ where all relevant data and metadata is comprised in a single, semantically-transparent and modular package. (I would like to thank Justin Littman for suggesting this term and for sharing access to his unpublished draft explaining the concept.) This helps ensure the portability of data between SFM instances; moving data for a collection set or collection to a new SFM instance is a simple matter of copying the containing folder and subfolders to a new location and running an import script. The SFM team’s decision to support this portability confers knock-on benefits, in that each collection or collection set is stored as a type of self-describing archival information packet. This is because SFM keeps an excellent record of its actions, as well as the actions of the users who configure the system right in the JSON files, fully serializing whatever information the database holds about a particular collection. To expand this point just a bit: SFM keeps records of configuration settings that were in place at a particular point in time. This data is kept in the historical tables, but is used to populate the JSON records contained in the records folder for each collection. For instance, if a collection contained ten seeds on May 10, 2016, but a user deleted three of those seeds and added six new ones on May 25, then added four more seeds on May 27, there would be three entries in the database: one for the current settings (until they are replaced) and two in the analogous historical seeds table. All of this is mirrored as key/value pairs to the “historicals_seeds” JSON file. Similarly, if a user stops collecting or changes the description of a collection, that action is recorded in the database and serialized to the JSON file. The figure below provides a simple example of system change data stored as a “historical seed” entry when a new seed was added to an existing collection.
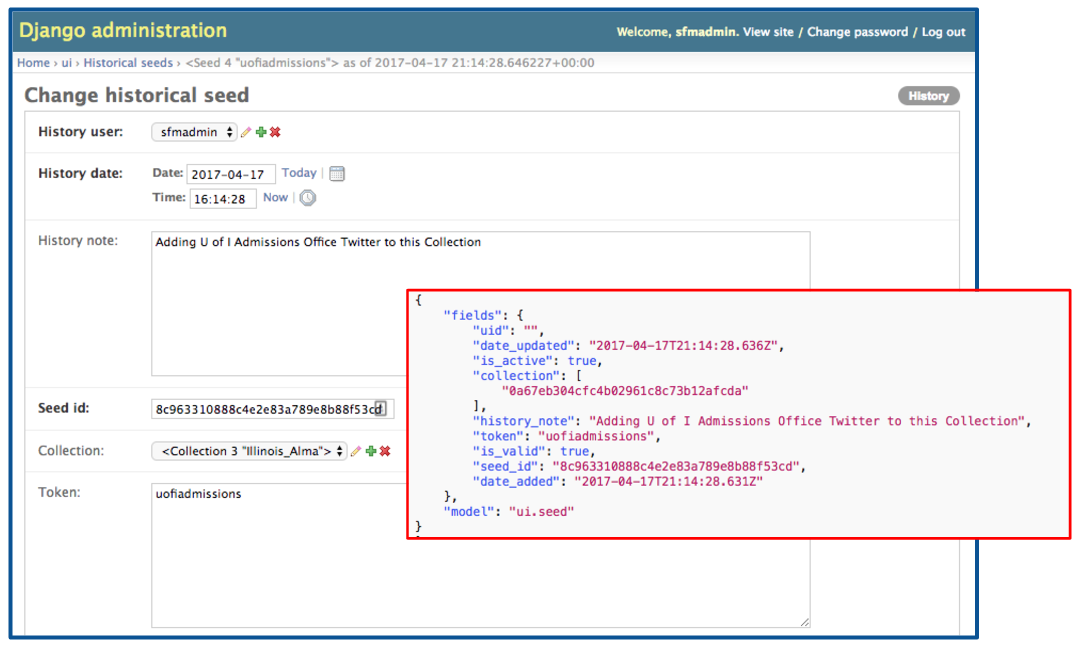
From an archivist’s perspective — as well as that of a future user of the records — this means that not only is SFM keeping a good record of provenance, it is making that record available in an easily preservable fashion, as an integral element of the package structure. The WARC and JSON files compose a submission information packet (SIP), to be used when the records are being ingested into another system. In essence, each collection set or collection contains many element of preservation metadata that one would need to preserve the bits over time and to allows users to make claims about their authenticity. For example, the JSON files include a record of prior collecting activities and an audit trail of actions taken by the people who have used the system to capture a particular set of social media posts. In fact, the packet could very nearly be considered to be ‘archival’ – that is to say, an archival information packet (AIP). The only thing missing is additional descriptive metadata, which should be supplied by an archivist in an external descriptive system.
While this point may seem rather academic, the fact that SFM keeps so much metadata about its actions allows us to differentiate between the social media posts that are captured and their value as records, in other words between a tweet and what might be called a ‘tweet record’. Users can know that each tweet is a particular fixing of a social media post, an outcome from the interaction between decisions made by a human user and the technology capturing records, at a particular point in time.
This has important implications: First, it provides a wealth of structured information that makes the objects preservable in just the way they were captured. But even more so, it provides a basis for making future judgements about their authenticity or completeness of what has been captured, a topic discussed in more detail in the export options and packaging recommendations sections of this report.
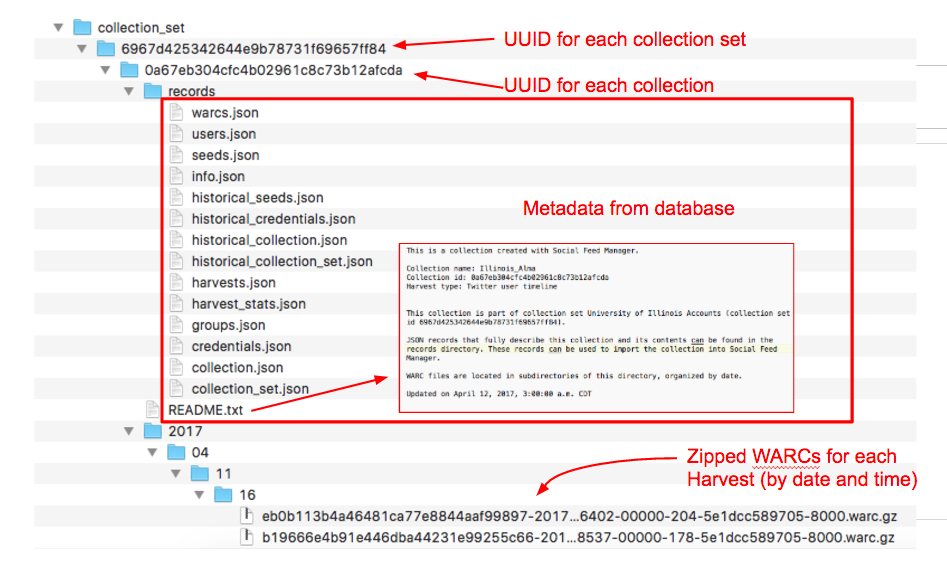
While the data model that SFM employs—tracking each action or harvest in a very hierarchical fashion—provides a well-structured data package, it also means that the data is stored in a complex folder structure, as shown in the figure below. (The implications of this for preservation and access are discussed more fully in the data exports and packaging sections of this report.)