As announced in this earlier post, we collected 280 million tweets with Social Feed Manager related to the 2016 U.S. presidential election and shared datasets of the tweet ids. This week, we loaded those tweets into TweetSets, a proof-of-concept tool that provides Twitter datasets for research and archiving. With TweetSets, users can filter/query existing datasets (such as the election datasets) to create custom datasets. Derivatives, such as a list of tweet ids, can then be generated for the custom dataset and downloaded.
A reminder: To conform with Twitter’s Developer Policies, non-GW researchers will only be able to download tweet ids, not the complete tweet. The complete tweet for a list of tweet ids can be retrieved using a tool like DocNow’s Hydrator.
One of the features of TweetSets is that it generates some basic statistics for a dataset to help with filtering. Here I will share the basic statistics for the election filter dataset, one of the datasets that are part of the election collection. The election filter dataset was collected between July 13, 2016 and November 10, 2016 from the Twitter filter stream tracking election2016, election, clinton, kaine, trump, pence and following @realDonaldTrump and @HillaryClinton.
Here’s a screenshot of all of the stats:
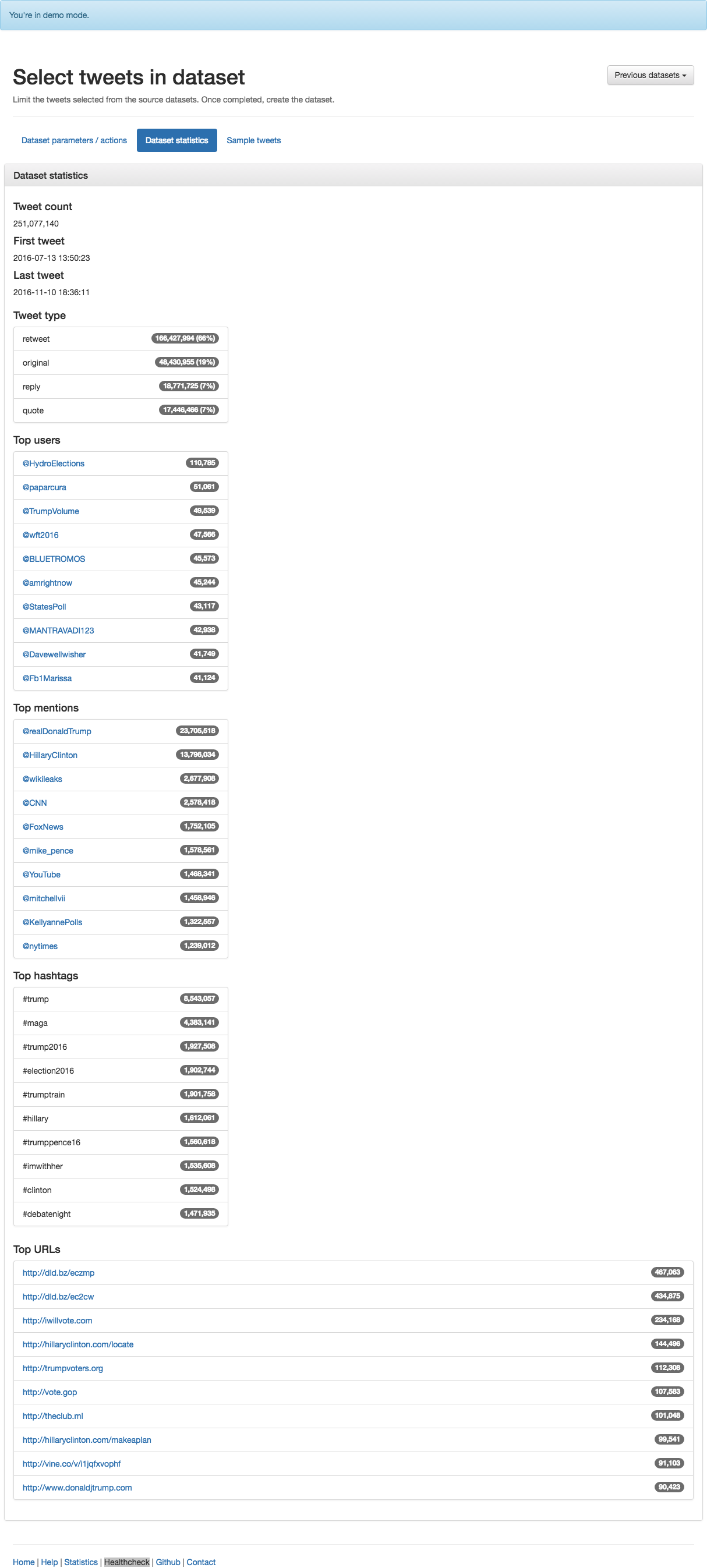
Here’s a breakdown of tweets in the dataset by tweet type:
| retweet | 166,427,994 | 66% |
| original | 48,430,955 | 19% |
| reply | 18,771,725 | 7% |
| quote | 17,446,466 | 7% |
Here are the most prolific tweeters in the dataset:
| @HydroElections | 110,785 |
| @paparcura | 51,061 |
| @TrumpVolume | 49,539 |
| @wft2016 | 47,566 |
| @BLUETROMOS | 45,573 |
| @amrightnow | 45,244 |
| @StatesPoll | 43,117 |
| @MANTRAVADI123 | 42,938 |
| @Davewellwisher | 41,749 |
| @Fb1Marissa | 41,124 |
What? The most prolific tweeter has 561K tweets but only 16 followers?
The most mentioned accounts are a bit less surprising (although @timkaine didn’t even crack the top 10):
| @realDonaldTrump | 23,705,518 |
| @HillaryClinton | 13,796,034 |
| @wikileaks | 2,677,908 |
| @CNN | 2,578,418 |
| @FoxNews | 1,752,105 |
| @mike_pence | 1,578,561 |
| @YouTube | 1,468,341 |
| @mitchellvii | 1,458,946 |
| @KellyannePolls | 1,322,557 |
| @nytimes | 1,239,012 |
It’s a landslide for Trump in the top hashtags:
| #trump | 8,543,057 |
| #maga | 4,383,141 |
| #trump2016 | 1,927,508 |
| #election2016 | 1,902,744 |
| #trumptrain | 1,901,758 |
| #hillary | 1,612,061 |
| #trumppence16 | 1,560,618 |
| #imwithher | 1,535,608 |
| #clinton | 1,524,498 |
| #debatenight | 1,471,935 |
Here’s the top URLs contained in tweets:
| http://dld.bz/eczmp | 467,063 |
| http://dld.bz/ec2cw | 434,875 |
| http://iwillvote.com | 234,168 |
| http://hillaryclinton.com/locate | 144,496 |
| http://trumpvoters.org | 112,308 |
| http://vote.gop | 107,583 |
| http://theclub.ml | 101,048 |
| http://hillaryclinton.com/makeaplan | 99,541 |
| http://vine.co/v/i1jqfxvophf | 91,103 |
| http://www.donaldjtrump.com | 90,423 |
The top 2 are just link spam.
The vine (http://vine.co/v/i1jqfxvophf) is gone from the live web, but is captured by the Internet Archive. http://theclub.ml now requires authentication but in captures by the Internet Archive it redirects to http://trumprally.club. Ditto with the two http://hillaryclinton.com URLS: gone from the live web but preserved by the Internet Archive. These demonstrate how critical the Internet Archive is for studying this sort of data and suggest that a useful approach may be to use Twitter data to seed web archiving.
Suffice to say, this dataset begs further study. You’re welcome to give it a try by filtering it with TweetSets or downloading it in its entirety.
Note about TweetSets: The servers that it is running on are not provisioned for heavy use, so be gentle. Please let me know about any problems that you encounter, as well as any comments or suggestions.
Thanks to Tables Generator for reducing the pain creating these markdown tables.