Social media data is collected to support social media research and to build social media archives. To date, most social media data collecting activity using APIs has focused on Twitter. I’d suggest that there are a number of reasons the Facebook Graph API has received less attention:
- Twitter is conceptually simpler. For Twitter the primary unit is a tweet. For Facebook, there is no single primary unit. Rather, there are pages, photos, videos, posts, comments, and more.
- Facebook has complicated, highly granular, poorly-documented privacy settings. (Poorly documented will be a recurring theme in this post.) Much Facebook data, especially of private citizens, is not publicly available.
- The Graph API is poorly documented (trust me, I’ve read the API docs of a fair number of social media platforms). I’ve discovered some areas where the docs don’t match the API and others in which there are features that are omitted from the docs.
- The Graph API is buggy and unreliable, especially for large or complex requests. Working with it requires trial and error and a ton of error handling code.
However, I would argue that the most significant reason that it has received less attention is because it is complicated and different from other social media APIs. While most platforms expose some flavor of a REST API, Facebook exposes a graph-based API. In a graph, the primary unit is a node. A node may be of different types (e.g., a page or a user). Depending on the type, a node will have different fields and edges. A field is an attribute of the node, e.g., name or description. An edge is a connection to another node, e.g., featured_video is a connection to another node (which is a video type) that is the featured video of the source node; comments is a connection to a set of nodes (which are comment type) that are the comments of the source node. (For a further discussion of why Twitter is the “model organism of big data” and why this is problematic, see Zeynep Tufekci’s “Big Data: Pitfalls, Methods and Concepts for an Emergent Field”.)
The challenge then for collecting data from the Facebook Graph API is how to “carve up” the graph. That is, when collecting a node, which of the node’s fields and edges should be collected. And given that a node’s edges can be followed to other nodes, which of the other nodes should be collected as well.
In this blog post I will describe f(b)arc, a python tool I wrote for collecting data from the Facebook Graph API. (In case you were wondering, the “b” is silent in f(b)arc.) For the purposes of this post, I will use the example of the Facebook page of Senator Mark Warner.
In addition to Mark Warner being a great senator, focusing on collecting his Facebook page supports my larger agenda of archiving the Facebook pages of all members of Congress (just as we archive the tweets of all members of Congress at GW Libraries.)
Brief introduction to the Graph API
Facebook provides the Graph API Explorer, a useful tool for working with the Graph API.
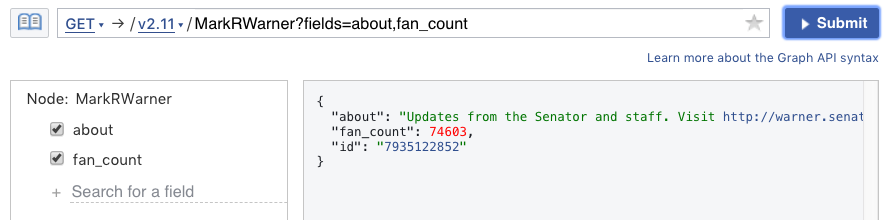
Here I request the node for Senator Warner’s page:

Each node has a numerical id, but some nodes also have string identifiers (e.g., “MarkRWarner”).
In addition, each node has a type. Depending on the type, the Graph API will return certain fields by default. In the case of the page, those fields are name and id, as shown above.
You can request specific fields for a node. Here I request the about and fan_count fields.
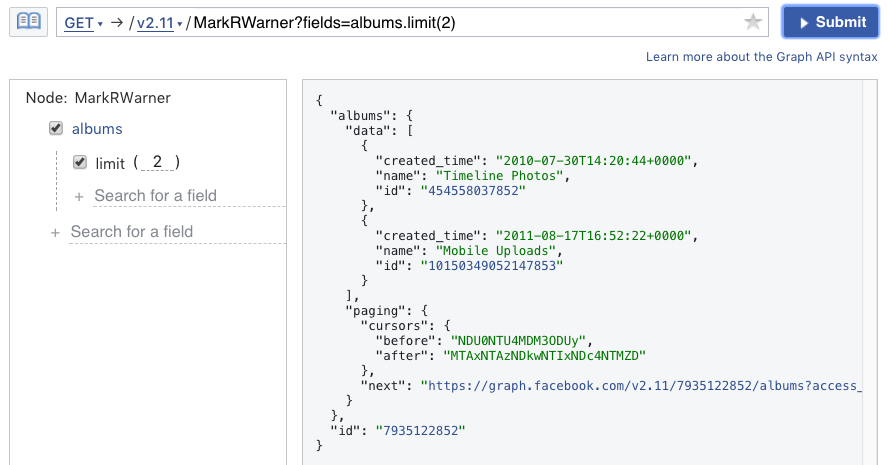
In addition to fields, you can also request edges for a node. Here I request the albums edge (limiting to 2 albums).
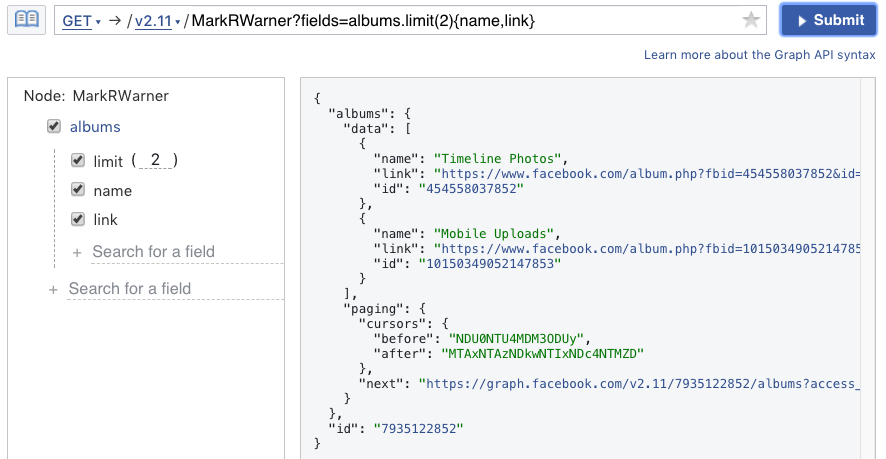
When requesting a connected node, you can also specify the fields or edges for a connected node. Here I request the name and link fields for the album nodes requested on the albums edge.
The Graph API is optimized to allow requesting just the data required with as few requests as possible. The goal is to make it efficient for a Facebook application (as apps are the primary user of the API) to interact with the Facebook platform.
There are some additional features of the Facebook API that are significant, but I won’t cover in this brief overview:
- You can learn about the edges and fields for a node type from the API docs or via introspection of the API. They often don’t agree.
- In addition to retrieving nodes, the Graph API supports updating and creating nodes.
- If a list contains many nodes, the Graph API only returns some of the nodes. Additional nodes can be retrieved with another call to the API using a process called “paging”. F(b)arc handles paging for you.
- Accessing the API requires an access token. There are a host of confusing token options. Token options for f(b)arc are described in the README.
Brief introduction to f(b)arc
The “special sauce” of f(b)arc is the node definitions. The node definitions specify which fields and edges will be retrieved for a given node type. Here’s a subset of the node definition for a photo:
definition = {
'fields': {
'can_backdate': {'omit': True},
'comments': {'edge_type': 'comment'},
'height': {},
'name': {'default': True},
}
}
The height has no settings. This means that this field is retrieved whenever a photo node is retrieved.
The name field has default set to true. In addition to retrieving this field whenever a photo node is retrieved, this field is also retrieved when getting an edge which is a photo. For example, an album node has a photos edge. When retrieving the photos edge, the name field (and other default fields are retrieved) for each photo.
The can_backdate field has omit set to true. This field is ignored. To aid with creating definitions, f(b)arc introspects the API to extract all of the fields and edges for a node type (see the metadata --template command; omitting is useful for keeping track of fields/edges that you have considered, but decided not to retrieve either because they require additional permissions or aren’t worth collecting.
The full definition for a photo has many more fields and edges. F(b)arc ships with definitions for albums, comments, events, live videos, pages, posts, photos, and videos. You can also add local definitions that override these default definitions.
Using f(b)arc
The graph command is used to retrieve the data for a node. For example, to retrieve the data for Senator Warner’s page, the command would be:
python fbarc.py graph page MarkRWarner
To execute this command, f(b)arc constructs a request based on the page definition. For larger edges, the API will not return all of the results at once; f(b)arc will follow the paging links to construct the entire node. As this may require many requests to the API, constructing the entire node may take some time.
By default, f(b)arc will only retrieve the requested node. Using the --levels argument, f(b)arc can be instructed to retrieve the nodes for edges as well. For example, if levels is set to 2, the photos, albums, events, videos, posts, and live videos from Senator Warner’s page will also be retrieved.
python fbarc.py graph page MarkRWarner --levels 2
Facebook data
Facebook data retrieved from the API is JSON. Here’s a snippet from a photo:
{
"id": "10155917661702853",
"metadata": {
"type": "photo"
},
"created_time": "2017-11-03T20:59:48+0000",
"link": "https://www.facebook.com/MarkRWarner/photos/a.490322322852.293145.7935122852/10155917661702853/?type=3",
"name": "#GetCovered at healthcare.gov, now through December 15th.",
"updated_time": "2017-11-18T01:13:33+0000",
"from": {
"name": "Senator Mark Warner",
"id": "7935122852"
},
"height": 360,
...
The full JSON is available here.
To assist with exploring data that has been retrieved from the Facebook Graph API, f(b)arc provides f(b)arc viewer, a simple web application for rendering the data, as well as navigating between connected nodes.
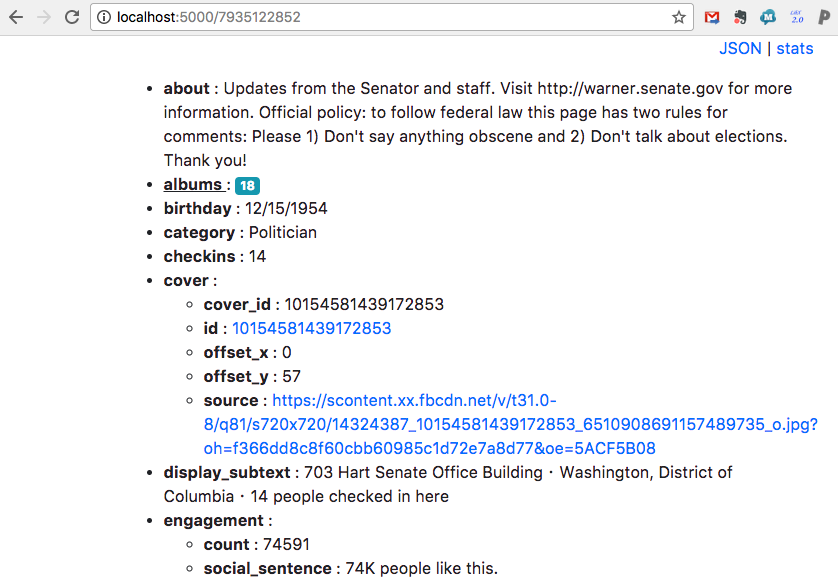
f(b)arc viewer can be launched with:
python fbarc_viewer.py my_fb_data.jsonl
Or the data retrieved by f(b)arc can be passed directly to the viewer:
python fbarc.py graph page TestyMcTestpage | python fbarc_viewer.py -
The data from Senator Warner’s page can be viewed here. (This is a static copy; let me know if you encounter any problems.)
Optimizations
Before introducing significant optimizations into f(b)arc, retrieving Senator Warner’s page and associated photos, videos, posts, comments, etc. took 47.5 hours. After optimizations, this was reduced to 87 minutes.
F(b)arc uses 3 types of optimizations:
- Edge limits: When requesting edges, the default number of items (aka “limit”) returned for that edge is fairly small. This requires requesting numerous page links to get all of the edge’s items. By setting the edge limit to a larger number, fewer pages must be retrieved to get all of the edge’s items.
- Page batches: The API supports batch requests, combining several requests to the API into a single request. F(b)arc combines multiple paging requests into a single batch request.
- Node batches: The standard request to the API is for a single node. However, using the
idsparameter, multiple nodes can be requested at the same time. F(b)arc combines requests for multiple nodes of the same type into a single request. The same result could be achieved with batch requests, but in testing using theidsparameter was faster.
All of these optimizations are configurable. So, for example, the number of photo nodes included in a node batch can be configured in the photo definition.
Rate limits
Like other social media platforms, Facebook does have rate limits on retrieving data from the API. These rate limits take two forms: (1) limits on the number of requests within a time period and (2) limits on the amount of data that can be returned in a single request.
In my work to date, I have only encountered rate limiting on the number of requests once. (At the time, for development reasons I was running multiple instances of f(b)arc with the same token.) To be considerate of the API and to avoid this rate limit, f(b)arc makes no more than 2 requests per second.
The second type of rate limit, limits on the amount of data that can be returned in a single request, occurs quite often. It takes the form of a “Please reduce the amount of data you’re asking for, then retry your request” error. Unfortunately, there is no way to know how much data will be returned by a request in advance. F(b)arc attempts to deal with this type of rate limit by using sensible defaults for edge limits and node batches. When it encounters this error, it retries by requesting a single node at a time.
Privacy
Like other consumers of the Graph API, f(b)arc must respect the privacy restrictions of the Facebook platform. These privacy restrictions prevent collecting non-public data, which on the Facebook platform is a significant amount of data. Most notably, user nodes, the nodes for the accounts of individual users, are restricted in the API.
This does not mean that all activities of individual users are restricted. Public comments, e.g., comments on a video posted on Senator Warner’s page, can be collected. Though these comments are public, they may still contain sensitive information that deserves ethical and privacy consideration.
API archiving vs. web archiving
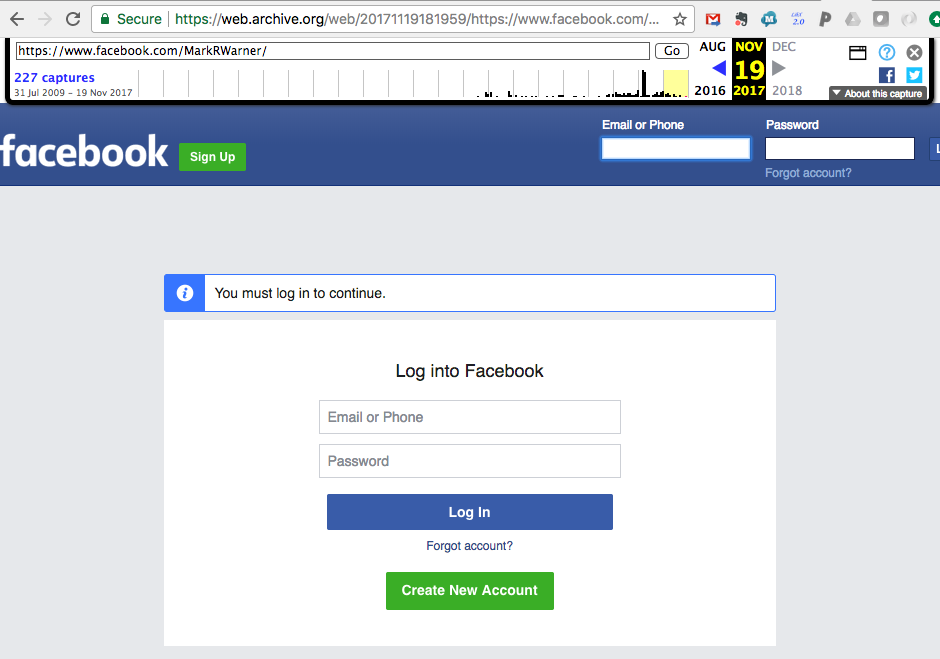
In an earlier blog post, I discussed the differences between web archiving and social media archiving. (Summary: in general, they are complementary archiving activities, with different strengths and weaknesses.) While different web archiving approaches may be more successful, in the case of the Internet Archive, Facebook capture of Senator Warner’s page is pretty grim. Here’s the most recent capture of Senator Warner’s page:
Feedback
For both the purposes of current research and to fulfill our obligation to preserve our cultural, social, intellectual, and political heritage, I am convinced that collecting data from the Facebook Graph API is imperative and a critical gap that must filled. I welcome feedback on f(b)arc and invite collaboration on its future development and/or use.