So it turns down that unchanging software accrues technical debt. In version 1.12.0 of SFM, we paid down some of that technical debt, changed directions on web harvesting and exploring data with SFM ELK, and added new features to make managing collections and citing datasets and SFM easier. Details below.
New features
First, the new features. In managing social media accounts two pain points emerged that motivated new features. The most significant of these was for Twitter user timeline collections. In earlier versions of SFM, accounts that were deleted, suspended, or protected would be detected and the user notified. The user could then delete these accounts from the collection. This, of course, proved burdensome for collections that contained thousands of accounts, especially when there was a lot of churn in those accounts (anything election related, for example). With this release, a user timeline collection can be configured to automatically delete problematic accounts. Don’t worry – you’ll still be notified and a record of the deleted account is maintained.

In addition, credentials sometimes become invalid, in which case it can’t be used any further for collecting. We encountered this regularly with Weibo and on occasion with Twitter. With this release, credentials can be deleted, preventing them from being used in any new collections. Again, don’t worry – a record of deleted credentials is maintained.
As the use of datasets collected with SFM in scholarly publishing has increased, we want to make it easier to cite those datasets and to cite SFM itself. On the footer, you will know find a link to our citation guidance. (Thanks Megan Potterbusch, GW’s Data Services Librarian, for assistance.)

Also, for datasets that have been publicly shared, e.g., by depositing in a data repository, a link to the public version of the dataset can now be added to the collection.

And lastly, we replaced our own code with Twarc’s json2csv for exporting tweets to tabular formats such as Excel and CSV. More fields are included for each tweet with json2csv and we’ll benefit from the community support of the code. It also means that you’ll be able to run the same export from SFM’s UI and from the command line. We’ve updated the Twitter data dictionary for this change.
Deprecated
In this release, we opted to deprecate both web harvesting and exploring data with SFM ELK (ElasticSearch, Logstash, Kibana). While the need for contemporaneous web archiving of web resources linked to from social media posts has become more evident, the approach of embedding Heritrix, a web crawler, was not the correct approach. While it worked for very limited harvesting of web resources, it was problematic to scale with deduping and regularly encountered errors. In the near future I intend to explore approaches for extracting URLs from tweets and sending them to web archiving platforms such as the Internet Archive. (Check out excellent research in this area by Alexander Nwala, ODU Web Science and Digital Libraries Research Group.)
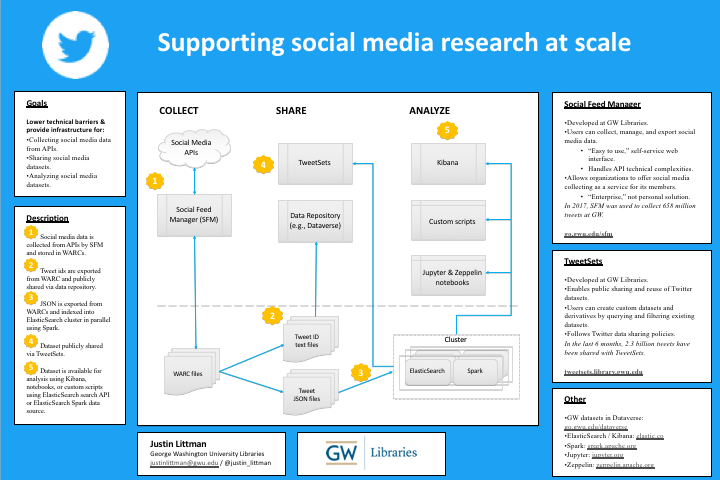
SFM ELK was an experiment with providing exploration, querying, analysis, and visualization of social media data. In earlier versions of SFM, it could be optionally enabled for a collection. The approach proved quite successful for a number of users, but scaling ElasticSearch within the SFM environment was too much work for the limited use it received as an experiment. However, within TweetSets, a companion project to SFM for sharing Twitter datasets, ElasticSearch is the primary datastore. Within TweetSets, I was able to focus on how to scale (viz., with a cluster) and how to load as fast as possible (viz., using Apache Spark). Once the tweets are indexed in ElasticSearch, Kibana can be pointed at it, providing similar functionality as SFM ELK. (If you need assistance getting started with TweetSets, let us know.)
On a related note, once tweets are loaded into TweetSets, they can be queried from other tools including Jupyter / Zeppelin notebooks and Spark. See my poster below from the Web Archiving and Digital Libraries (WADL) conference.
Technical debt
In earlier versions of SFM, we took the approach of pinning every single dependency possible, including Docker containers, operating system packages, and python libraries. Naturally, these evolved over time, with new versions becoming available and some pinned versions becoming unavailable. Unfortunately, keeping everything pinned proved too unwieldy, especially for python libraries where the dependency graph is unclear. To simplify this, we relaxed some of the pinning of operating system packages and removed the pinning of transitive python libraries. This allowed us to more easily upgrade a number of containers, packages, and libraries in this release. (Still, outstanding, is an upgrade to Python 3 and Django latest.)
Also falling in the technical dept category are some updates to the documentation and the Docker containers. Thanks to Miranda Smith (ODU) for pointing out discrepancies in running the smoke tests and Justin Patterson (Penn State) for helping troubleshoot clean shutdown of Docker containers.
We will continue to prioritize user feedback in future SFM releases, so please reach out.