Version 1.2 of Social Feed Manager will contain a passel of improvements to our social media harvesters. The social media harvesters are services that run within SFM and handle the collecting of social media data from social media APIs and recording it in WARC files. These improvements work was motivated by our own experience running SFM at scale (160 million+ #election tweets so far!), as well as feedback from our partners conducting testing of SFM (thanks Internet Archive!). In particular, we are trying to address the following:
- Graceful handling of expected and unexpected shutdowns of harvesters. In previous versions, unexpected shutdowns would kill a harvest and the harvest would not be resumed when the harvester was brought back up. For both expected and unexpected shutdowns, the counts that were kept of collected social media and the state that was maintained on harvesting might be out of sync with the social media data that was recorded in WARC files. The lack of a graceful way to shut down harvesters also made upgrades of SFM tricky.
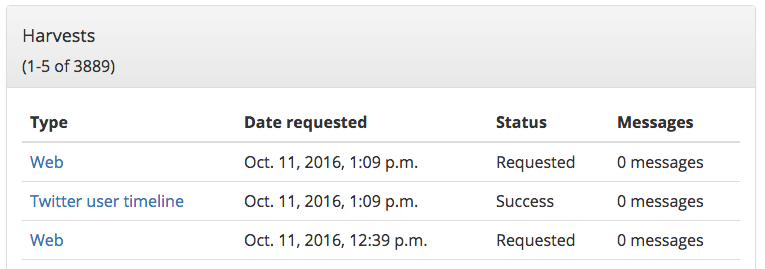
- Better feedback to users on the status of harvests. In the previous version, most harvests displayed “requested” until the harvest was completed.
- Better handling of long-running harvests, especially Twitter searches. In the previous version, harvests were recorded in a single WARC file, meaning the entire harvest would be lost if an error occurred. Since a broad Twitter search might take a few days to complete, this was problematic. (Note: This did not apply to long-running Twitter stream harvests, as they are handled differently.)
- Better handling of harvest errors. In particular, we observed cases where Twarc would get stuck in a retry loop on odd network problems (DNS, certificate) that don’t resolve. (Twarc is the social media client that SFM uses to access the Twitter APIs.)
Let’s start with how harvesters used to work. (For the purposes of simplifying the description, I’m going to omit the handling of Twitter stream harvests.)
- Harvester received a harvest request message. The harvest request message contained all of the information that the harvester needed to do its work. The information included the credentials to use, the seeds to collect, and the location to write the WARC files.
- Harvester retrieved any state from the state store that is relevant to the harvest. In the current implementation, the state store is just a JSON file that is stored on disk. An example of state might be the last tweet id that was retrieved for a user timeline.
- An instance of Warcprox was instantiated. Warcprox is a web proxy that acts as a “man-in-the-middle” between the social media client and the social media API.
- A social media client (e.g., Twarc) made requests to the API. Warcprox recorded the HTTP transaction to a WARC file. The harvester kept counts of social media items, extracts URLs from the social media items, and when done, updated the state store.
- When the social media client completed, Warcprox was terminated. Warcprox closed the WARC file.
- Harvester sent a harvest status message. The harvest status message contained the outcome of the harvest, counts of social media items and WARC files, and some messages about the harvest.
- Harvester sent a web harvest request message containing the URLs that were extracted from the social media items. A web harvester would receive this request message and perform a harvest of the URLs.
- Harvester looked for completed WARC files. For each WARC file it found, the harvester moved the file into the collection’s directory and sent a WARC created message. (Other services use the WARC created message. For example, the SFM ELK service uses it to trigger loads.)
The crux of the problem is that the harvesting actions such as reporting status, making counts, and updating the state store were independent from adding a WARC file to the collection. Further, they were based on the social media items returned by the social media client, rather than the social media items recorded in the WARC files that had been added to the collection. There were numerous circumstances where they could get (slightly) out of sync.
In version 1.2, the harvesters have been re-architected to account for the problems described above. Here’s how the new harvesters work:
- Harvester receives a harvest request message.
- Harvester writes the harvest request message to disk.
- Harvester sends a harvest status message indicating that the harvest is running.
- Harvester retrieves any state from the state store that is relevant to the harvest.
- An instance of Warcprox is instantiated.
- A social media client makes requests to the API. Warcprox records the HTTP transaction to a WARC file.
- Concurrently, a separate thread looks for completed WARC files and adds them to a queue of WARC files to be processed.
- Concurrently, a separate thread processes queued WARC files. For processing:
- Harvester iterates over the social media items in the WARC file; during the iteration, counts of social media items are kept, URLs are extracted from the social media items, and the state store is updated (but not persisted to disk).
- Harvester sends a web harvest request message.
- Harvester moves the WARC file into appropriate location in the collection’s directory.
- Harvester persists the state store to disk.
- Harvester sends a WARC created message.
- Harvester sends a harvest status message indicating the harvest is running and providing the latest counts, etc.
- Harvester persists the result (social media item counts, messages, etc.) so far to disk, in case the harvest needs to be resumed.
- When the social media client is completed, Warcprox is terminated.
- Harvester waits for processing of all WARC files to complete.
- Harvester sends a final harvest status message indicating that the harvest has completed.
- Harvester deletes harvest request message from disk.
If on startup, a harvester finds an existing harvest message on disk it repeats the harvest. The harvest uses the persisted state and results, which are in sync with the last WARC file that was added to the collection. Thus, the harvester better handles shutdowns, automatically repeating the harvest and resuming from a consistent state. In addition, the harvester more regularly sends harvest status messages (including as soon as the harvest is started), so the user receives more timely updates.
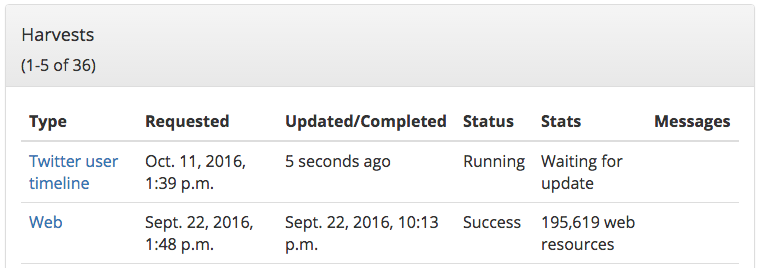
To better handle long-running harvests, we made an enhancement to Warcprox (we have our own fork) that rolls over WARC files based on time. Thus, every 30 minutes the existing WARC file is closed and a new WARC file is created. (This is configurable.)
To better handle handle harvest errors, we added retries to the harvester. If an error is received from the social media client, the harvester will try up to 3 times to perform the harvest. (This is configurable.) For each try, it returns to the last known good state of the harvest. In addition, we enhanced Twarc to limit the number of times it will retry the Twitter API when an error occurs. (This enhancement can be found in release 0.8.1 of Twarc.)
With these changes in place, we’re looking forward to hammering away at SFM again. Fortunately, #election2016 is giving us plenty of fodder to practice large scale collecting.